 Xuhang Fan (Shawn)
Xuhang Fan (Shawn)Gneezy, Uri, Silvia Saccardo, Marta Serra-Garcia和Roel van Veldhuizen. 《Bribing the Self》. Games and Economic Behavior 120 (2020年3月1日): 311–24. https://doi.org/10.1016/j.geb.2019.12.010.
摘要
研究问题:自我欺骗👉有偏建议;自我欺骗能力的相关因素;自我欺骗抑制
自我欺骗如何在帮助专家保持自我形象时导致偏见
自我欺骗能力相关:自我欺骗的存在;自我欺骗能力的局限(自我欺骗需要借口)
Parameter Panel:激励机会的提供时间点;自我欺骗的借口数量
实验综述
专家向客户推荐投资中,根据推荐获得佣金
Treatment:改变专家得知存在激励的时间点 → 当动机先于提供建议时,他们更可能产生偏见
论文意思是结果和自我欺骗理论一致(在评估投资建议前就了解激励会影响顾问对投资的信念和偏好)
自我欺骗只要有哪怕很小的借口都存在,但所有借口消失时会消失
如何约束自我欺骗来促进优质建议
1 Introduction
专家建议很重要
在医疗、法律和财务决策等各种领域决策都很重要
【文献】在存在模糊性或主观性的情况下,个体可能会从事自私自利的行为,这使他们能够保持积极的社会或自我形象
(e.g., Kunda, 1990; Konow, 2000; Dana et al., 2007; Haisley and Weber, 2010; Di Tella et al., 2014; Exley, 2015; Grossman and van der Weele, 2017; Gneezy, Saccardo and van Veldhuizen, 2018; Zou, 2018; Bicchieri, Dimant and Sonderegger, 2019)
研究道德顾虑究竟出自对自我形象的担忧(self-image concerns)还是社会形象的担忧(social-image concerns)
探究自我欺骗能力的限制 (所谓借口的多少 ways to convince themselves)
RiskReturn experiment :risk-return tradeoff √ trade-off between their commission and the client’s expected loss √
Dominance experiment :
risk-return tradeofftrade-off between their commission and the client’s expected loss √ObviousDominance experiment:None
实验结论
专家们会主动扭曲自己的信念,使自己能够推荐存在激励的选择
这里面的信念扭曲呢?
为减少错误建议比率,任何自我欺骗的借口余地都必须被消除
研究结果可以帮助法规设计、探讨削弱委员会对建议的影响
通过减少判断中的主观性,或通过强化由有偏见的建议引起的自我形象成本,来减少自我欺骗的范围的干预,需要精心设计,以减少不诚实建议的程度
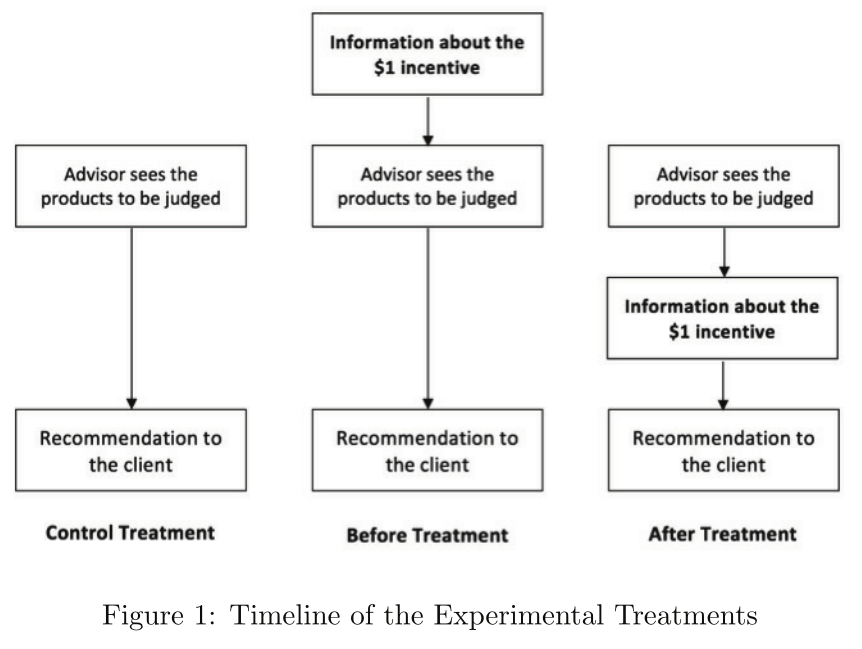
实验设计
The Advice Game(Sender & Receiver Game)
选择发送一条投资建议A或B
Excuse Experiment
Risk-Return
A —— a 50-50 lottery between $2 and $4
B —— a 50-50 lottery between $1 and $7
Dominance Experiment
A —— a 50-50 lottery between $2 and $4
B —— a 50-50 lottery between $2 and $6
Obvious-Dominance Experiment
A —— a 50-50 lottery between $2 and $4
B —— a 50-50 lottery between $5 and $7
Treatment:根据自欺动机(NO/Before/After)
Control T.;Before T.;After T.
结果预测
Hypothesis 1: In the Risk-Return, recommend A(Before) > **A(After)
S-D=Risk Preference+Fairnes
Hypothesis 2A: In the Dominance, recommend A(Before) = A(After)
S-D==Risk Preference
Hypothesis 2B: In the Dominance, recommend A(Before) > A(After)
S-D==Fairness
Hypothesis 3: In the Obvious-Dominance, recommend A(Before) = A(After)
实验结果
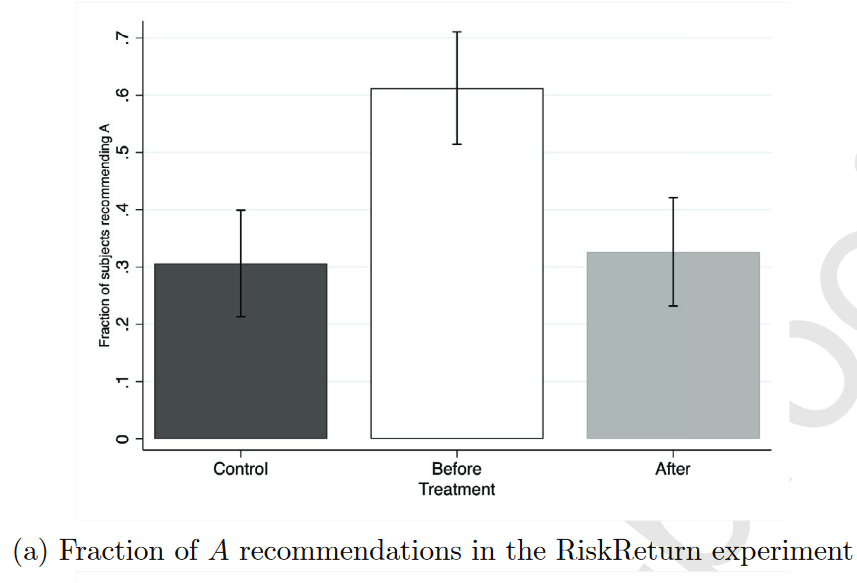
The Risk-Return Experiment
Hypothesis 1. 成立
选择A(激励性选项)比例为:
Control=30.6%
Before=61.2%
After=32.7%
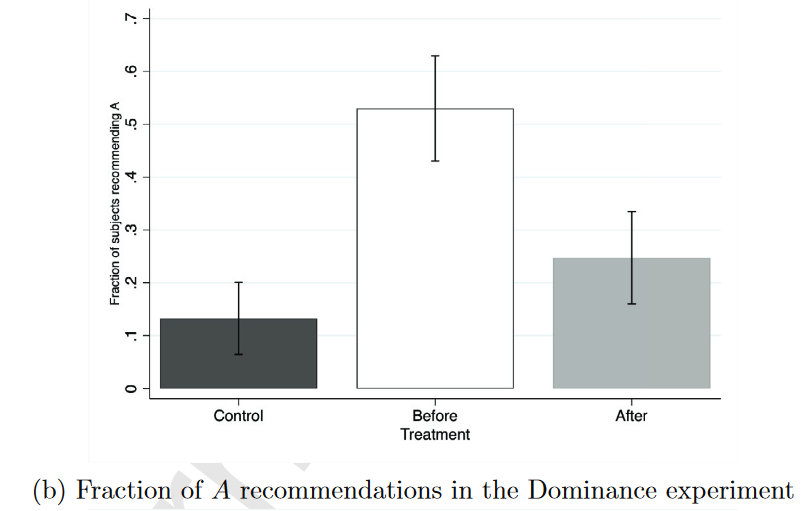
The Dominance Experiment
选择A(激励性选项)比例为:
Control=13.3%
Before=53%
After=24.7%
DID 图片
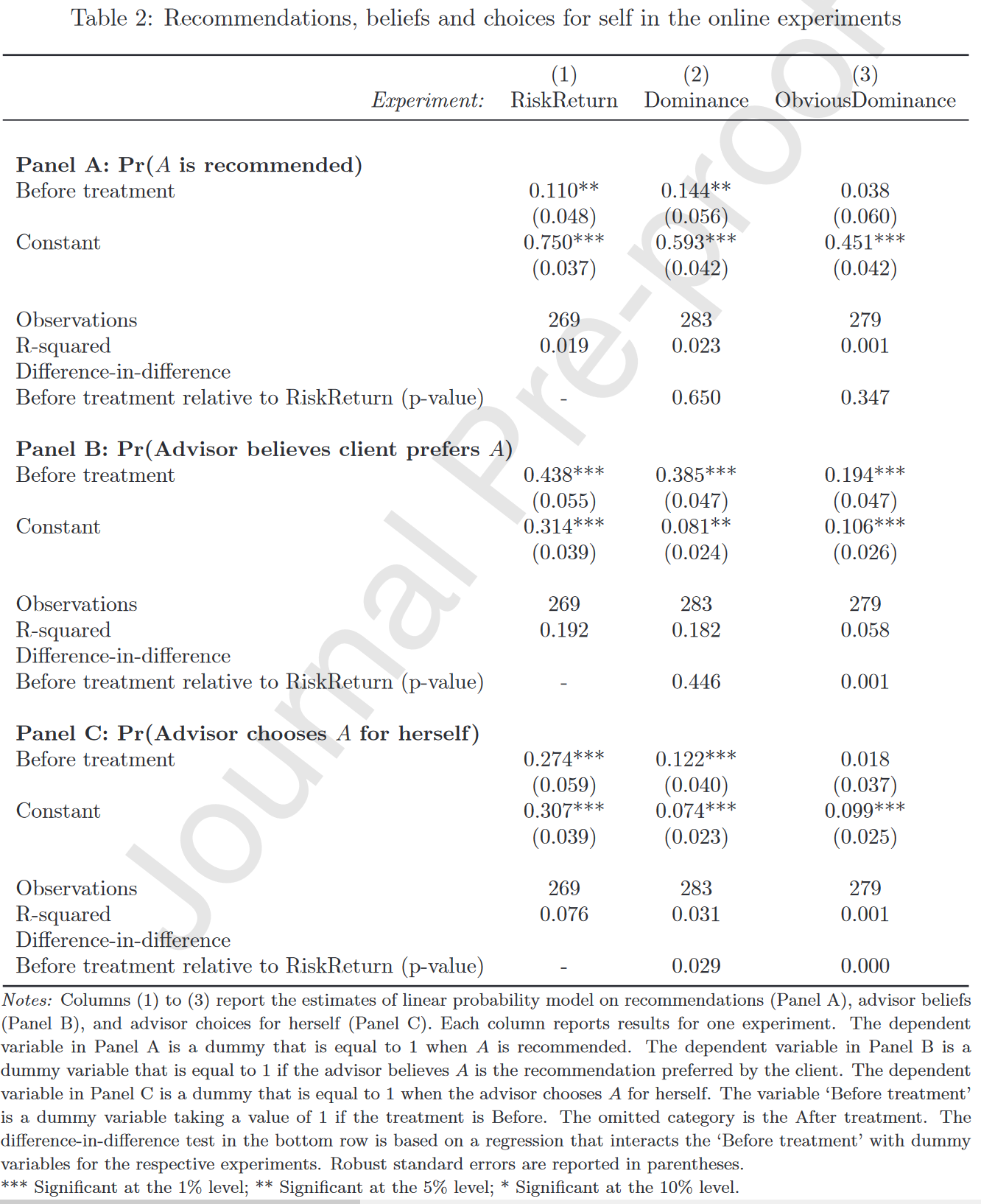
Difference-in-difference:compare the effect of the Before and Control treatments on recommendations in the Dominance experiment to those in the Risk-Return experiment
the coefficient Before treatment X Dominance 接近0且不显著
说明自我欺骗哪怕只有一点点机会都可以实现
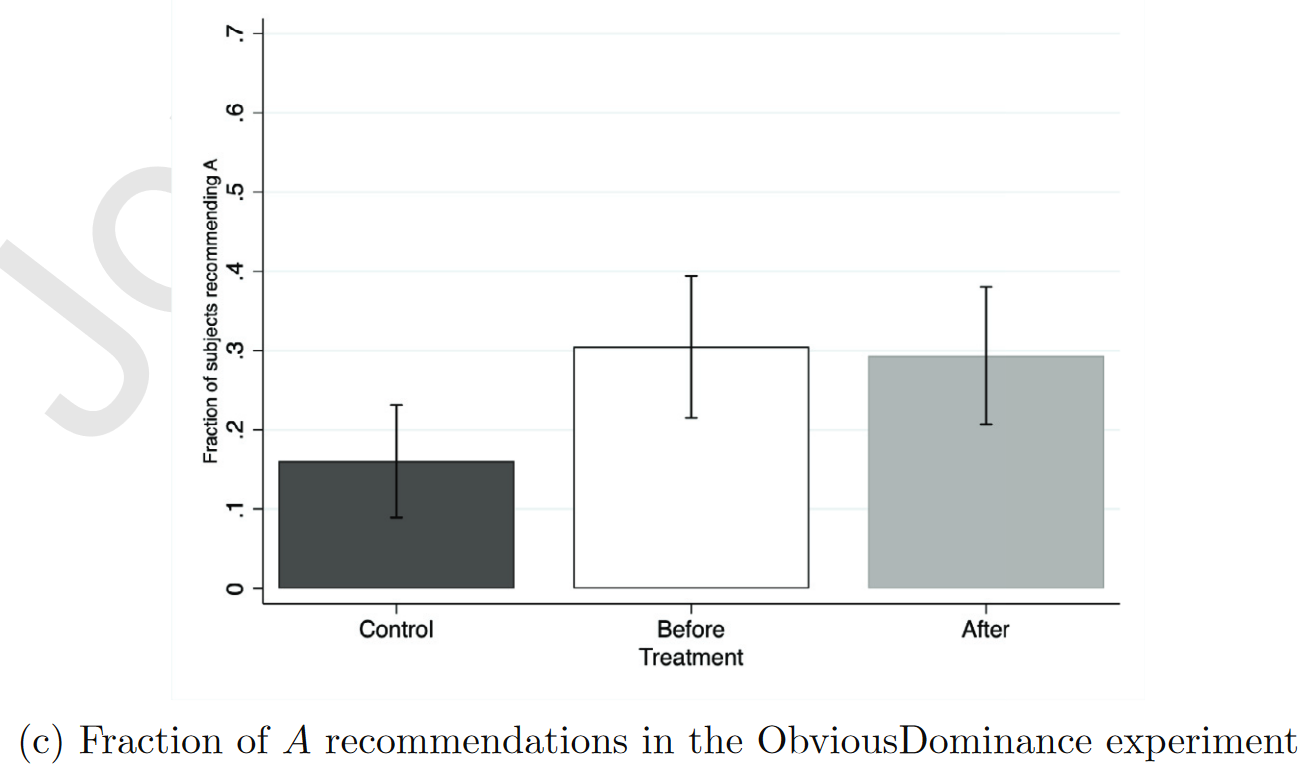
The Obvious-Dominance Experiment
选择A(激励性选项)比例为:
Control=16%
Before=30.5%
After=29.4%
Mechanisms of Self-Deception: Belief Distortion and Choice for Self
自我欺骗的直接证据
实验设计
Three Experiments (RiskReturn, Dominance and ObviousDominance) × Before & After
被试决策前提取信念:你认为被试更喜欢哪个选择?
paradigm Babcock et al. (1995)
没有激励信念??那被试完全可以欺骗实验者啊
作者做了一个辩解:存在文献说明激励和不激励信念结果都一样(e.g., Friedman and Massaro, 1998; Sonnemans and Offerman, 2001; Trautmann and van de Kuilen, 2014; Hollard, Massoni and Vargnaud, 2016)
但是这里是有欺骗实验者的动机的!不应该这样
最后要求被试自己做一个选择获得收益(随机抽1实现)
Risk-Return experiment
investment A was a 50-50 lottery between $0.50 and $1
Investment B was a 50-50 lottery between $0.25 and $1.75
Dominance experiment
investment A was a 50-50 lottery between $0.50 and $1
Investment B was a 50-50 lottery between $0.50 and $1.50
Obvious-Dominance Experiment
investment A was a 50-50 lottery between $0.50 and $1
Investment B was a 50-50 lottery between $1.25 and $1.75
实验结果
Beliefs
自欺动机强的普遍推荐A率高,而且Before和After差距大
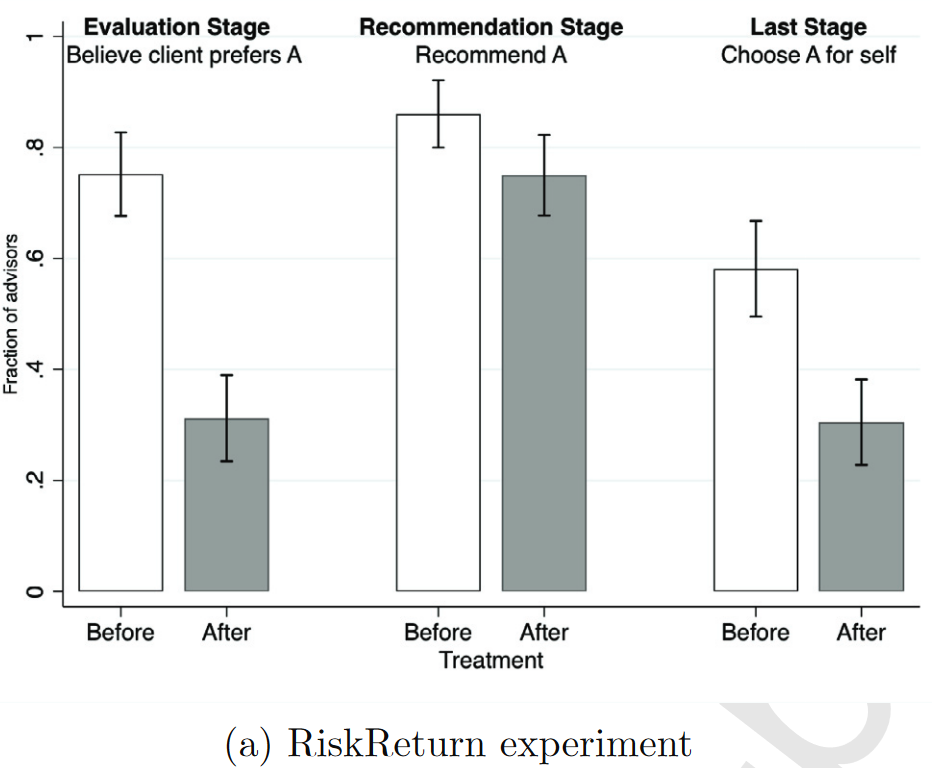
RiskReturn
Preferrable Choice(Before)==75.2%; Preferrable Choice(After)==31.4%;
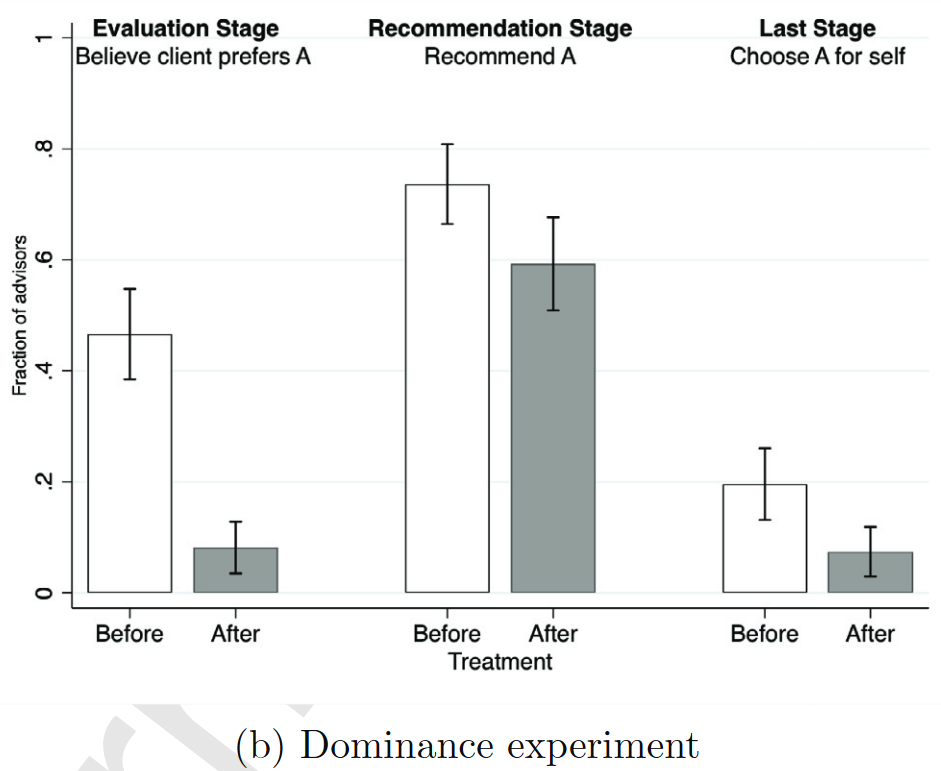
Dominance
Preferrable Choice(Before)==46.6%; Preferrable Choice(After)==8.1%;
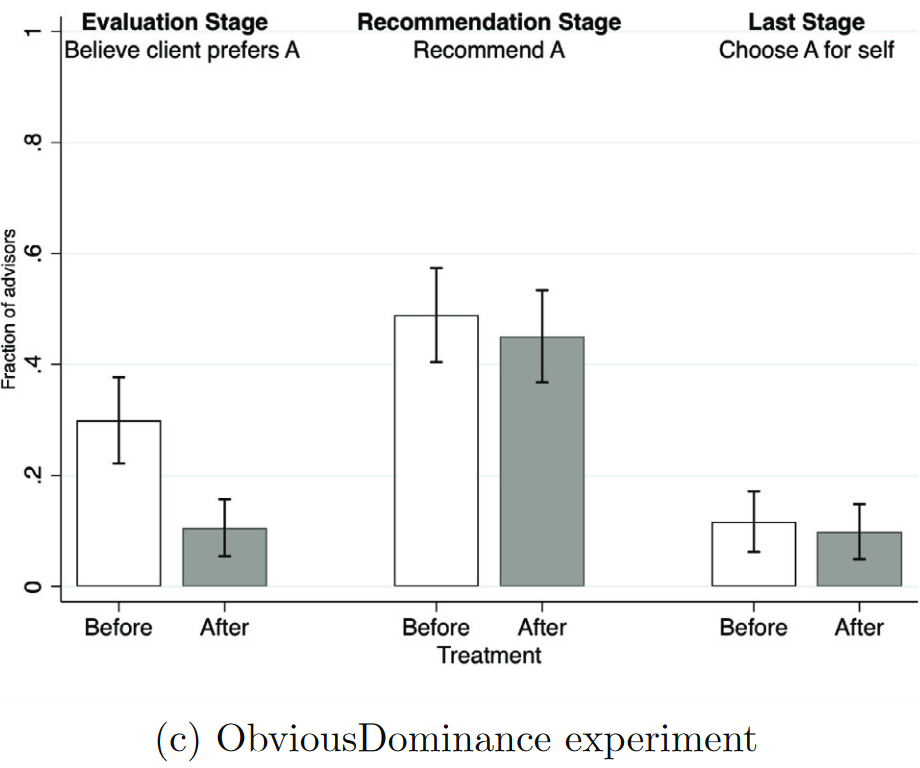
ObviousDominance
Preferrable Choice(Before)==29.9%; Preferrable Choice(After)==10.6%;
Recommendations
网上实验结果复现了线下的结果;但是Before和After差距变小
Choice for Self.
RiskReturn
Choose A=58.1%(Before); 30.7%(After)
Dominance
Choose A=19.6%(Before); 7.4%(After)
ObviousDominance
no gap in A choices
Choose A=11.7%(Before); 9.9%(After)
Discussion
Stylized Framework ——Benabou (2015)
- 专家会从选择、推荐选项一致中获得自我形象效用
- 自我欺骗采取观察者有偏信念更新(Biased Updating)的形式
Cost Of Self-Deception
文章的理论模型假设自我欺骗成本是常数(默认是0)
假设在后期研究中可以放宽来缩小 the scope for self-deception
Conclusion
相关文献:专家的错误建议;激励扭曲判断
(Steinman et al., 2001; Moore et al., 2010; Cain, Loewenstein and Moore, 2011; see also Malmendier and Schmidt, 2017)
Belief-Based Utility
(e.g., Loewenstein and Molnar, 2018; B ́enabou and Tirole, 2016; Golman et al., 2016; Mobius et al. 2014)
过度治疗的抑制
先让专家有选择,再让专家得知欺骗动机
评价和反思
自我欺骗的信念测度问题
自我欺骗的是不是要测度出信念的矛盾(Belief Distortion)
本文只有一个信念(比较的是Before和After)
自我欺骗的信念测度不用激励?
没有激励很可能欺骗研究者(换成精准测度范式的话又和Nudge相似)
没有提供个体层面的精准测度
- Before和After的存在的确促进了有偏推荐——但是一部分本就风险偏好的人他们的选择被忽视了(只要你本来就想推荐风险偏好的选项,那就不需要做任何trade-off)
